
在深度神经网络与神经元网络行业,科学研究工作人员一般 离不了 GPU。归功于 GPU 极高内存带宽和较多关键数,科学研究工作人员能够迅速地得到实体模型训炼的結果。此外,CPU 受制于本身较少的关键数,测算运作必须较长的時间,因此不适感用以深度神经网络实体模型及其神经元网络的训炼。
但近日,莱斯大学、小蚂蚁集团公司和intel等组织 的学者发布了一篇毕业论文,说明了在消費级 CPU 上运作的 AI 手机软件,其训炼深层神经元网络的速率是 GPU 的 15 倍。这篇毕业论文已被 MLSys 2021 大会接受。
毕业论文连接:
https://proceedings.mlsys.org/paper/2021/file/3636638817772e46b59d74cff571fbb3-Paper.pdf
毕业论文通讯作者、莱斯大学布郎工程学校的电子信息科学终身教授 Anshumali Shrivastava 表明:「训炼成本费是 AI 发展趋势的关键短板,一些企业每星期就需要耗费数百万美元来训炼和调整 AI 工作中负荷。」她们的此项科学研究致力于处理 AI 发展趋势中的训炼成本费短板。

Anshumali Shrivastava。
深层神经元网络(DNN)是一种强劲的人工智能技术,在一些每日任务上超过了人们。DNN 训炼一般 是一系列的矩阵乘法计算,是 GPU 理想化的工作中负荷,速率大概是 CPU 的 3 倍。
现如今,全部领域都致力于改善并完成迅速的矩阵乘法计算。科学研究工作人员也都是在找寻专业的硬件配置和构架来促进矩阵乘法,她们乃至在探讨用以特殊深度神经网络的专用型硬件配置 - 手机软件局部变量。
Shrivastava 领导干部的试验室在 2019 年保证了这一点,将 DNN 训炼变换为可以用哈希表处理的检索难题。她们设计方案的亚线形深度神经网络模块(sub-linear deep learning engine, SLIDE)是专业为运作在消費级 CPU 上而设计方案的,Shrivastava 和intel的合作方在 MLSys 2020 大会上就发布了该技术性。她们表明,该技术性能够超过根据 GPU 的训炼。
在 MLSys 2021 交流会上,学者讨论了在当代 CPU 中,应用矢量化和系统优化网络加速器是不是能够提升 SLIDE 的特性。
毕业论文一作、莱斯大学 ML 博士研究生 Shabnam Daghaghi 表明:「根据哈希表的加快早已超过了 GPU。大家运用这种自主创新进一步促进 SLIDE,结果显示即便不致力于矩阵计算,还可以运用 CPU 的工作能力,而且训炼 AI 实体模型的速率是特性最好专用型 GPU 的 4 至 15 倍。」

Shabnam Daghaghi。
除此之外,毕业论文二作、莱斯大学电子信息科学与数学课本科毕业生 Nicholas Meisburger 觉得,CPU 依然是测算行业最广泛的硬件配置,其对 AI 的奉献没法估算。
在本毕业论文中,该科学研究再次了解了在2个当代 Intel CPU 上的 SLIDE 系统软件,掌握 CPU 在训炼大中型深度神经网络实体模型层面的真实发展潜力。该科学研究容许 SLIDE 运用当代 CPU 中的矢量化、量化分析和一些系统优化。与未提升的 SLIDE 对比,在同样的硬件配置上,该科学研究的优化工作产生了 2-7 倍的训炼時间加快。
SLIDE 的工作内容包含:复位、前向-反向传播和哈希表升级。下面的图 1 为前向-反向传播工作流程图:
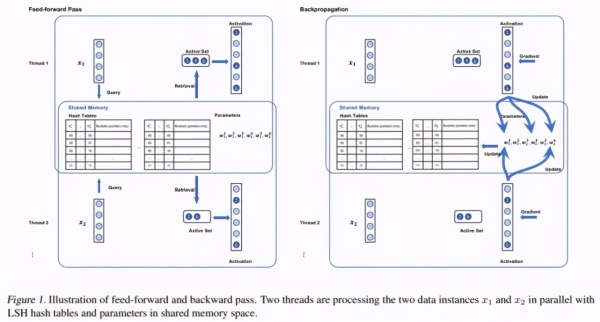
前向和后向散播平面图。
该科学研究致力于规模性评定,在其中需要的神经元网络有着数亿个主要参数。在两部 Intel CPU 上较为了提升的 SLIDE,分别是 Cooper Laker 网络服务器(CPX)和 Cascade Lake 网络服务器(CLX),并与下列下列 5 个标准开展了比照:
1)V100 GPU上的 full-softmax tensorflow 完成;
2) CPX 上的 full-softmax tensorflow 完成;
3)CLX 上的 full-softmax tensorflow 完成;
4)CPX 上的 Naive SLIDE;
5)CLX 上的 Naive SLIDE。
在其中,CPX 是intel第三代酷睿i5可拓展CPU,适用根据 AVX512 的 BF16 命令。CLX 版本号更老,不兼容 BF16 命令。
学者在三个真正的云计算平台集在评定了架构和别的标准。Amazon670K 是用以推荐算法的 Kaggle 数据;WikiLSH-325K 数据和 Text8 是 NLP 数据。详尽数据统计见下表 1:

针对 Amazon-670K 和 WikiLSH-325K,学者应用了一个规范的全连接神经元网络,掩藏层尺寸为 128,在其中键入和輸出全是好几个热编号空间向量。针对 Text8,该科学研究应用规范 word2vec 语言模型,掩藏层尺寸为 200,在其中键入和輸出分别是一个热编号空间向量和好几个热编号空间向量。
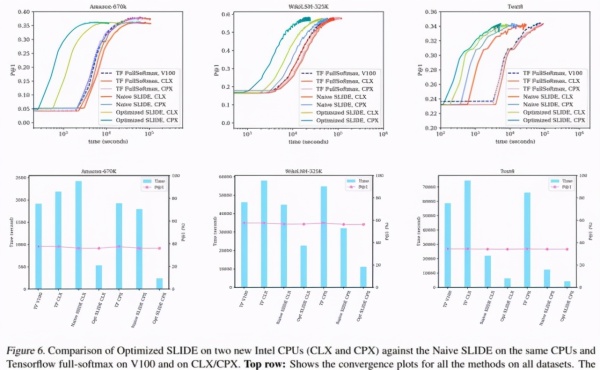
下面的图 6 第一行意味着全部数据的時间收敛性图,数据显示了该科学研究明确提出的提升 SLIDE 在 CPX 和 CLX(墨绿色和淡绿色)上训炼時间好于别的标准 。图 6 的底端行表明了全部数据的柱形图。
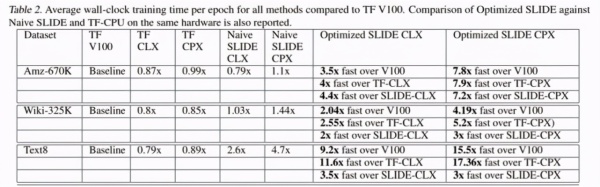
下表 2 得出了三个数据上的详尽标值結果:
下表 3 中,学者展现了 BF16 命令对每一个 epoch 均值训炼時间的危害。结果显示,在 Amazon-670K 和 WikiLSH325K 上,激话和权重值中应用 BF16 命令各自将特性提高了 1.28 倍和 1.39 倍。可是,在 Text8 上应用 BF16 沒有造成危害。

下表 4 展现了有没有 AVX-512 时,提升 SLIDE 在三个数据上的每一个 epoch 均值训炼時间比照。结果显示,AVX-512 的矢量化将均值训炼時间降低了 1.2 倍。






