

此文是按照源码Python3.9来写,其中有些assert语句与一些不必要的宏字段会删除,保留核心的逻辑并添加注释,方便自己和大家理解。在代码中都会注明源码出处方便大家完整阅读。
| 目录 | 概要 |
|---|---|
| Demo | 采用了Python的演示应用程序 |
| Doc | 文档 |
| Grammer | Python的语法文件 |
| Include | 编译Python时引用的各种头文件 |
| Lib | 标准附加库 |
| Mac | Mac用的工具等 |
| Misc | 很多文件的集合(如gdbinit和vimrc等) |
| Modules | Python的C语言扩展模块 |
| Objects | Python的对象用的C语言代码 |
| PC | 依存于OS等环境的程序 |
| PCbuild | 构造Win32和x64时使用 |
| Parser | Python用的解析器 |
| Python | Python的核心 |
Python是一门动态的、一切皆对象的语言,这些内存申请可能会产生大量小的内存,为了加快内存操作和减少内存碎片化,使用Python自己的内存管理器,叫PyMalloc。
- # Objects/obmalloc.c 代码注释
- /* An object allocator for Python.
- Here is an introduction to the layers of the Python memory architecture,
- showing where the object allocator is actually used (layer +2), It is
- called for every object allocation and deallocation (PyObject_New/Del),
- unless the object-specific allocators implement a proprietary allocation
- scheme (ex.: ints use a simple free list). This is also the place where
- the cyclic garbage collector operates selectively on container objects.
- Object-specific allocators
- _____ ______ ______ ________
- [ int ] [ dict ] [ list ] ... [ string ] Python core |
- +3 | <----- Object-specific memory -----> | <-- Non-object memory --> | # 对象特有的内存分配器
- _______________________________ | |
- [ Python's object allocator ] | |
- +2 | ####### Object memory ####### | <------ Internal buffers ------> | # Python对象分配器
- ______________________________________________________________ |
- [ Python's raw memory allocator (PyMem_ API) ] |
- +1 | <----- Python memory (under PyMem manager's control) ------> | | # Python低级内存分配器
- __________________________________________________________________
- [ Underlying general-purpose allocator (ex: C library malloc) ]
- 0 | <------ Virtual memory allocated for the python process -------> | # 通用的基础分配器(如glibc的malloc等)
- =========================================================================
- _______________________________________________________________________
- [ OS-specific Virtual Memory Manager (VMM) ]
- -1 | <--- Kernel dynamic storage allocation & management (page-based) ---> | # OS特有的虚拟内存管理器
- __________________________________ __________________________________
- [ ] [ ]
- -2 | <-- Physical memory: ROM/RAM --> | | <-- Secondary storage (swap) --> | # 物理内存和交换目的地(如HDD等)
- */
- PyDict_New() // 第三层
- PyObject_GC_New() // 第二层
- PyObject_Malloc() // 第二层
- new_arena() // 第一层
- malloc() // 第零层
- ////////////////////////////////////////以下2层属于操作系统范畴,不在讨论范围/////////////////////////////////
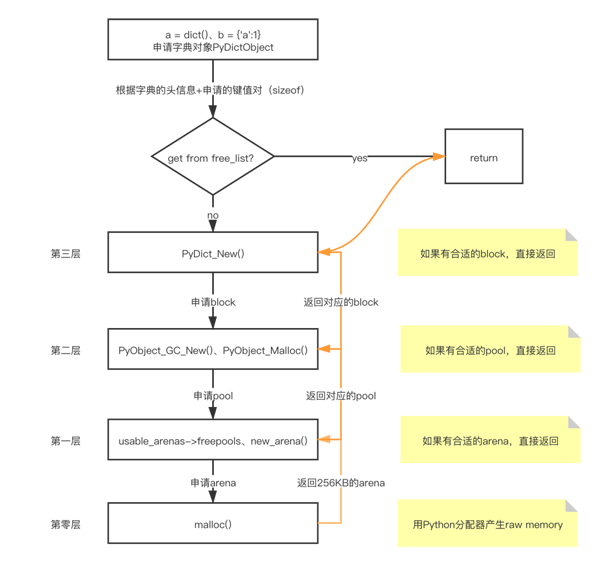
图1
- //Objects/obmalloc.c
- #define SMALL_REQUEST_THRESHOLD 512
- #define NB_SMALL_SIZE_CLASSES (SMALL_REQUEST_THRESHOLD / ALIGNMENT)
- /* Largest positive value of type Py_ssize_t. */
- #define PY_SSIZE_T_MAX ((Py_ssize_t)(((size_t)-1)>>1))
- static void *
- _PyObject_Malloc(void *ctx, size_t nbytes)
- { // 走Python的分配器,函数进去就会有判断(0,512]的才使用
- void* ptr = pymalloc_alloc(ctx, nbytes);
- if (LIKELY(ptr != NULL)) {
- return ptr;
- }
- // 大于512字节走C的malloc,函数进去进做了越界判断,Py_ssize_t为阈值
- ptr = PyMem_RawMalloc(nbytes);
- if (ptr != NULL) {
- raw_allocated_blocks++;
- }
- return ptr;
- }
在源代码中以PyMem_为前缀的所有函数是封装C语言提供给Python语法使用的,其核心使用的就是第0层malloc之类的C库函数。
当Python在WITH_MEMORY_LIMITS编译符号打开的背景下进行编译时,Python内部的另一个符号会被激活,这个名为SMALL_MEMORY_LIMIT的符号限制了整个内存池的大小,同时,也就限制了可以创建的arena的个数。
在默认情况下,不论是Win32平台,还是unix平台,这个编译符号都是没有打开的,所以通常Python都没有对小块内存的内存池的大小做任何的限制。
- [obmalloc.c]
- #ifdef WITH_MEMORY_LIMITS
- #ifndef SMALL_MEMORY_LIMIT
- #define SMALL_MEMORY_LIMIT (64 * 1024 * 1024) /* 64 MB -- more? */
- #endif
- #endif
- #ifdef WITH_MEMORY_LIMITS
- #define MAX_ARENAS (SMALL_MEMORY_LIMIT / ARENA_SIZE)
- #endif
有了以下的宏定义,我们写代码的时候只需要提供类型和数量,而不用自己去计算具体需要申请多少空间
- //Include/pymem.h
- #define PyMem_New(type, n) \
- ( ((size_t)(n) > PY_SSIZE_T_MAX / sizeof(type)) ? NULL : \
- ( (type *) PyMem_Malloc((n) * sizeof(type)) ) )
- #define PyMem_NEW(type, n) \
- ( ((size_t)(n) > PY_SSIZE_T_MAX / sizeof(type)) ? NULL : \
- ( (type *) PyMem_MALLOC((n) * sizeof(type)) ) )
- #define PyMem_Resize(p, type, n) \
- ( (p) = ((size_t)(n) > PY_SSIZE_T_MAX / sizeof(type)) ? NULL : \
- (type *) PyMem_Realloc((p), (n) * sizeof(type)) )
- #define PyMem_RESIZE(p, type, n) \
- ( (p) = ((size_t)(n) > PY_SSIZE_T_MAX / sizeof(type)) ? NULL : \
- (type *) PyMem_REALLOC((p), (n) * sizeof(type)) )
- #define PyMem_Del PyMem_Free
- #define PyMem_DEL PyMem_FREE
每次申请内存的时候一定不会每次都遇到刚好的块去分配,那么一下一大块内存会被切割使用,那么中间会产生很多小的但是可能不在会被使用的碎片(但是整个加起来也是一个大的可使用的块),而且每次查找合适的块需要遍历整个堆,所以为了减少碎片和快速分配内存,我们需要内存管理。
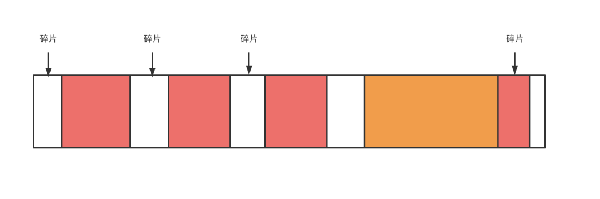
图2
小于512字节的内存申请由Python的低级分配器接管(空白内存,raw memory),做了3级层次的划分,依次为block、pool、arena

图3
pool与arena头与boby连接的不同

图4
现在来到的是真正Python的内存管理谈论的部分了,Python内存管理做了哪些处理
arena
“ 第一层的核心就是创建arena
arena的大小
arena的默认值是256K
- #define ARENA_BITS 18 /* 256 KiB */
- #define ARENA_SIZE (1 << ARENA_BITS)
- // Objects/obmalloc.c
- struct arena_object {
- // arena_object地址
- uintptr_t address;
- // 将arena的地址用于给pool使用而对齐的地址
- block* pool_address;
- // 该arena中可用pool的数量
- uint nfreepools;
- // 该arena中所有pool的数量
- uint ntotalpools;
- // 使用完毕的pool,用单链表维护
- struct pool_header* freepools;
- // 双向链表指针
- struct arena_object* nextarena;
- struct arena_object* prevarena;
- };
为什么arena_object需要address和pool_address2个字段?
“ 上面内存管理的划分提到arena_object与body是不连续的,图4
pool_header被申请时,它所管理的block集合的内存一定也被申请了;所以他是连续的一块空间
但是当aerna_object被申请时,它所管理的pool集合的内存则没有被申请;arena需要指针相连
所以address指定的是头数据,pool_address指定的是真实数据开始的位置,所以不同
new_arena
类型
“ uintptr_t 是由从 C99 开始导入的 stdint.h 提供的,在将 C 指针转化成整数时,它起着很大的作用。uintptr_t 正是负责填补这种环境差异的。uintptr_t 会根据环境变换成 4 字节或 8 字节,将指针安全地转化,避免发生溢出的问题。
- // uchar 和 uint 分别是 unsigned ××× 的略称。
- #undef uchar
- #define uchar unsigned char /* 约8位 */
- #undef uint
- #define uint unsigned int /* 约大于等于16位 */
- #undef ulong
- #define ulong unsigned long /* 约大于等于32位 */
- #undef uptr
- #define uptr Py_uintptr_t
- typedef uchar block;
- //[obmalloc.c]
- // arenas管理着arena_object的集合
- static struct arena_object* arenas = NULL;
- // 当前arenas中管理的arena_object的个数
- static uint maxarenas = 0;
- // “未使用的”arena_objectd单向链表
- static struct arena_object* unused_arena_objects = NULL;
- // “可用的”arena_object链表
- static struct arena_object* usable_arenas = NULL;
- // 初始化时需要申请的arena_object的个数
- #define INITIAL_ARENA_OBJECTS 16
- //[obmalloc.c]
- static struct arena_object*
- new_arena(void)
- {
- struct arena_object* arenaobj;
- uint excess; /* number of bytes above pool alignment */
- // 初始化默认值为NULL,需要生成arena_objects
- if (unused_arena_objects == NULL) {
- uint i;
- uint numarenas;
- size_t nbytes;
- // 确定申请arena的个数,初始化得到16个,之后会2倍扩容
- numarenas = maxarenas ? maxarenas << 1 : INITIAL_ARENA_OBJECTS;
- // 溢出判断
- if (numarenas <= maxarenas)
- return NULL;
- nbytes = numarenas * sizeof(*arenas);
- if (nbytes / sizeof(*arenas) != numarenas)
- return NULL;
- // 需要使用0层的分配器分配numarenas个数arena_object(头信息)所需的raw memory
- // 分配完后arenas作为静态全局变量
- arenaobj = (struct arena_object *)realloc(arenas, nbytes);
- if (arenaobj == NULL)
- return NULL;
- arenas = arenaobj;
- // 把以上分配的raw memory,维护到unused_arena_objects单向链表中
- for (i = maxarenas; i < numarenas; ++i) {
- // arena地址,如果没有分配就用0作为标识符
- arenas[i].address = 0;
- // 最后一个arena指向NULL,其余都指向下一个指针,初始化分配是一个连续的单链表
- arenas[i].nextarena = i < numarenas - 1 ? &arenas[i+1] : NULL;
- }
- /* 反映到全局变量中 */
- unused_arena_objects = &arenas[maxarenas];
- maxarenas = numarenas;
- }
- ////////////////////////////////////以上完成了arenas 的初始化,如下图所示//////////////////////////////////////////
- // 从unused_arena_objects链表中取出一个“未使用的”arena_object(表头)
- arenaobj = unused_arena_objects;
- unused_arena_objects = arenaobj->nextarena;
- assert(arenaobj->address == 0);
- // 分配一块arena内存,256KB
- // 这时候address有具体地址了
- arenaobj->address = (uptr)malloc(ARENA_SIZE);
- ++narenas_currently_allocated;
- if (arenaobj->address == 0) {
- // 分配失败,让把拿出来的头放回到unused_arena_objects链表中
- arenaobj->nextarena = unused_arena_objects;
- unused_arena_objects = arenaobj;
- return NULL;
- }
- ///////////////////////////////以上是分配arena空间与arena_object连接///////////////////////////////////////
- // 将arena内的空间分割为各个pool
- arenaobj->freepools = NULL;
- /* pool_address 对齐后开头pool的地址
- nfreepools 对齐后arena中pool的数量 */
- arenaobj->pool_address = (block*)arenaobj->address;
- arenaobj->nfreepools = ARENA_SIZE / POOL_SIZE;
- // 内存对齐
- excess = (uint)(arenaobj->address & POOL_SIZE_MASK);
- if (excess != 0) {
- --arenaobj->nfreepools;
- arenaobj->pool_address += POOL_SIZE - excess;
- }
- arenaobj->ntotalpools = arenaobj->nfreepools;
- return arenaobj;
- }
- /////////////////////////////////////////以上是划分pool/////////////////////////////////////////////////////
1、初始化16个arena_object

图5
2、扩容
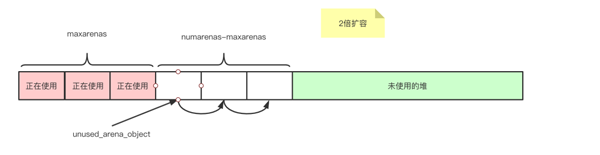
图6
3、分配arena空间,就是arena表头与真实数据相连
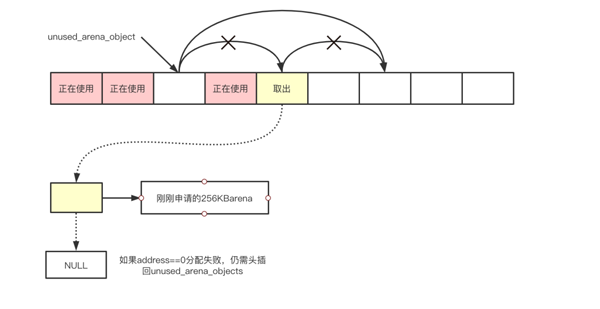
图7
4、给arena划分pool,excess是什么-内存对齐会消耗一个pool
结构体 arena_object 的成员 pool_address 中存有以 4K 字节对齐的 pool 的地址。
在此使用 POOL_SIZE_MASK 来对用 malloc() 保留的 arena 的地址进行屏蔽处理,计算超过的量(excess)。
如果超过的量(excess)为 0,因为 arena 的地址刚好是 4K 字节(2 的 12 次方)的倍数,所以程序会原样返回分配的 arena_object。这时候因为 arena 内已经被 pool 填满了,所以可以通过计算 arena 的大小或 pool 的大小来求出 arena 内 pool 的数量。
如果超过的量不为 0,程序就会计算“arena 的地址 + 超过的量”,将其设置为成员pool_address。此时 arena 内前后加起来会产生一个 pool 的空白,nfreepools--。

图8
“ arena_object是否与pool建立联系导致状态不同
unused_arena_object(未使用状态)
usable_arenas(可用状态)
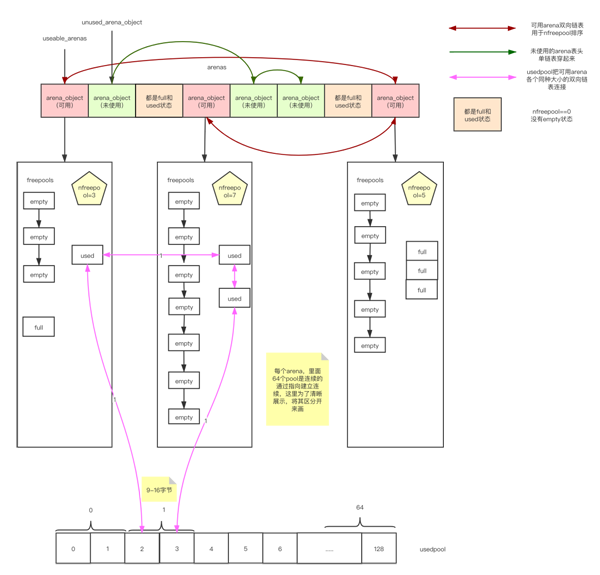
图9
“ 第 2 层的分配器负责管理 pool 内的 block。这一层实际上是将 block 的开头地址返回给申请者,并释放 block 等。
一个pool被分割成一个个的block。Python中生成对象时,最终都会被分一个或几个block上。block是Python内存分配的最小单元
大小以8个字节为梯度的内存块,就是类保证内存对齐(字对齐)
1、提高了CPU的读写速度
2、减少了碎片大小(必不可少的浪费)
- // 以下的宏
- // 索引为0的话, 就是1 << 3, 显然结果为8
- // 索引为1的话, 就是2 << 3, 显然结果为16
- #define INDEX2SIZE(I) (((uint)(I) + 1) << ALIGNMENT_SHIFT)
- * Request in bytes Size of allocated block Size class idx
- * ----------------------------------------------------------------
- * 1-8 8 0
- * 9-16 16 1
- * 17-24 24 2
- * 25-32 32 3
- * 33-40 40 4
- * 41-48 48 5
- * 49-56 56 6
- * 57-64 64 7
- * 65-72 72 8
- * ... ... ...
- * 497-504 504 62
- * 505-512 512 63
所以当我们需要申请44个字节的内存空间的时候,PyObject_Malloc会从内存池中划分一个 48 字节的block使用
- //Objects/obmalloc.c
- #define ALIGNMENT 8 /* must be 2^N */
- #define ALIGNMENT_SHIFT 3
“ 我们可以从图8里看到excess是为了在arena中pool4K大小的对齐,所以block以8字节的倍数自然都是对齐的
由于pool_header中szidx确定
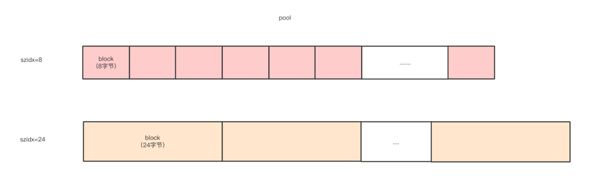
图10
CPU 原则上能从对齐的地址取出数据。相应地,malloc() 分配的地址也应配合 CPU 对齐来返回数据。
利用这一点的著名 hack 就是将地址的低 3 位用作标志。
假设在结构体内存入某个指针。如果从 malloc() 返回的地址是按 8 字节对齐的,那么其指针的低 3 位肯定为“0”。于是我们想到了在这里设置位,将其作为标志来使用。当我们真的要访问这个指针时,就将低 3 位设为 0,无视标志。
这是一个非常大胆的 hack,但事实上 glibc malloc 却实现了这个 hack。
block 有3种状态管理
未使用:未使用自然没有链表的指向了,那么我们只能在pool_head上设置第一个可以使用块的偏移量nextoffset

图11
pool是与系统页一样的4KB的大小,其中一个pool只能管理一个种规格的block,由szidx字段来标识。所以pool是具有size概念的block集合
- //Objects/obmalloc.c
- #define SYSTEM_PAGE_SIZE (4 * 1024)
- #define SYSTEM_PAGE_SIZE_MASK (SYSTEM_PAGE_SIZE - 1)
- #define POOL_SIZE SYSTEM_PAGE_SIZE /* must be 2^N */
- #define POOL_SIZE_MASK SYSTEM_PAGE_SIZE_MASK
在讲解arena初始化的时候第4部分讲到了excess就是为了做pool的内存对齐,可见图8。这里就不在赘述
一个pool的头由48个字节组成,所有的pool以双向链表的形式连接
- //Objects/obmalloc.c
- /* When you say memory, my mind reasons in terms of (pointers to) blocks */
- typedef uint8_t block;
- /* Pool for small blocks. */
- struct pool_header {
- union { block *_padding;
- uint count; } ref; /* 当前pool里面已分配出去的block数量 */
- block *freeblock; /* 指向空闲block链表的第一块 */
- struct pool_header *nextpool; /* next和prev提供usedpool使用,减少缓存表的空间 */
- struct pool_header *prevpool;
- uint arenaindex; /* 自己所属的arena的索引(对于arenas而言) */
- uint szidx; /* 分配的block的大小,所以pool中的所有块大小一致 */
- uint nextoffset; /* 下一个可用block的内存偏移量 */
- uint maxnextoffset; /* 最后一个block距离开始位置的偏移量 */
- };
- typedef struct pool_header *poolp;

图12
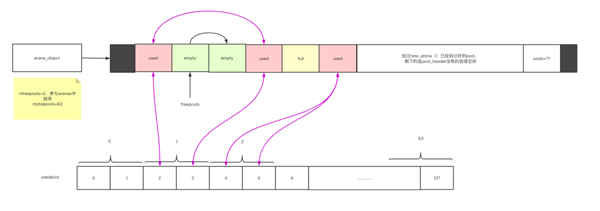
图13
“ 作用就是管理所有used状态的pool
- // poolp大概是pool_header的指针型的别名。也就是说,usedpools 是 pool_header 的指针型的数组。
- typedef struct pool_header *poolp;
宏 NB_SMALL_SIZE_CLASSES
- #define ALIGNMENT 8 /* 有必要为2的N次方 */
- #define SMALL_REQUEST_THRESHOLD 512
- // 指明了在当前的配置之下,一共有多少个size class。
- #define NB_SMALL_SIZE_CLASSES (SMALL_REQUEST_THRESHOLD / ALIGNMENT)
usedpools的初始化大小
- // 这个宏定义了一个指针,这个指针指向的位置是从一组的开头再往前“两个 block 指针型的大小”。
- #define PTA(x) ((poolp )((uint8_t *)&(usedpools[2*(x)]) - 2*sizeof(block *)))
- // 宏 PT() 以两个一组的形式调用宏 PTA()。
- #define PT(x) PTA(x), PTA(x)
- // usedpools数组有128个
- static poolp usedpools[2 * ((NB_SMALL_SIZE_CLASSES + 7) / 8) * 8] = {
- PT(0), PT(1), PT(2), PT(3), PT(4), PT(5), PT(6), PT(7)
- #if NB_SMALL_SIZE_CLASSES > 8
- , PT(8), PT(9), PT(10), PT(11), PT(12), PT(13), PT(14), PT(15)
- #if NB_SMALL_SIZE_CLASSES > 16
- , PT(16), PT(17), PT(18), PT(19), PT(20), PT(21), PT(22), PT(23)
- #if NB_SMALL_SIZE_CLASSES > 24
- , PT(24), PT(25), PT(26), PT(27), PT(28), PT(29), PT(30), PT(31)
- #if NB_SMALL_SIZE_CLASSES > 32
- , PT(32), PT(33), PT(34), PT(35), PT(36), PT(37), PT(38), PT(39)
- #if NB_SMALL_SIZE_CLASSES > 40
- , PT(40), PT(41), PT(42), PT(43), PT(44), PT(45), PT(46), PT(47)
- #if NB_SMALL_SIZE_CLASSES > 48
- , PT(48), PT(49), PT(50), PT(51), PT(52), PT(53), PT(54), PT(55)
- #if NB_SMALL_SIZE_CLASSES > 56
- , PT(56), PT(57), PT(58), PT(59), PT(60), PT(61), PT(62), PT(63)
- #if NB_SMALL_SIZE_CLASSES > 64
- #error "NB_SMALL_SIZE_CLASSES should be less than 64"
- #endif /* NB_SMALL_SIZE_CLASSES > 64 */
- #endif /* NB_SMALL_SIZE_CLASSES > 56 */
- #endif /* NB_SMALL_SIZE_CLASSES > 48 */
- #endif /* NB_SMALL_SIZE_CLASSES > 40 */
- #endif /* NB_SMALL_SIZE_CLASSES > 32 */
- #endif /* NB_SMALL_SIZE_CLASSES > 24 */
- #endif /* NB_SMALL_SIZE_CLASSES > 16 */
- #endif /* NB_SMALL_SIZE_CLASSES > 8 */
- };
现在以为usedpool的角度出发来看
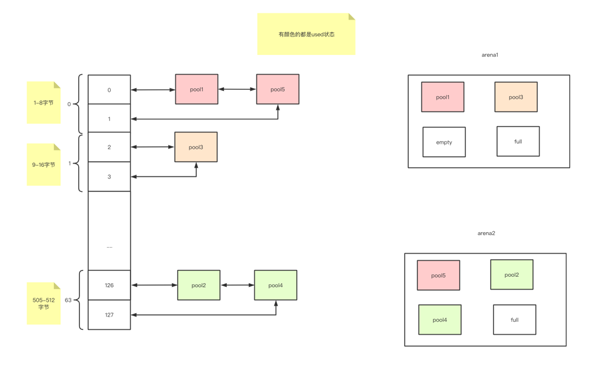
图14
used就是把使用了至少一个块,但是还没有全部使用完的pool整合到一个usedpool中,那么这一个做法类似以hash表的链地址法,通过下标可以O(1)到达同一size的usedpool[下标]的位置,然后使用链表,因为empty->used和used->full,方便插入和删除pool
一个例子
1、当申请20个字节内存的时候,Python会首先获得size class index,通过size = (uint )(nbytes \- 1) >> ALIGNMENT_SHIFT,其中ALIGNMENT_SHIFT是内存对齐的需要右移3位(即8字节对齐),得到(20-1)>>3=2
2、通过usedpools[i+i]->nextpool可以快速找到一个最合适当前内存需求的pool
- byte = 20 /* 申请的字节数*/
- byte = (20 - 1) >> 3 /* 对齐:结果 2 */
- pool = usedpools[byte+byte] /* 因为是两两一组,所以索引加倍: index 4 */ // O(1)
- // 这时,取出的 pool 存在如下关系。
- pool; == pool->nextpool
- pool; == pool->prevpool
- pool->nextpool == pool->prevpool // O(1)
在需要缓存的时候,能够尽可能地让缓存少承载一些引用表。(只需要pool_header中两个内部的指针成员,next和prev)
如果直接保留 pool_header 的话,往往就会出现 usedpools 变得太大,缓存承载不下的状况。因为我们要频繁引用数组 usedpools,所以让它小一些才会减轻缓存的压力。
通过尽量不使用那些可用空间多的内存空间,增加了使其完全变为空的机会。如果这部分内存空间完全为空,那么就能将其释放。
在释放的时候从pymalloc_free函数观察来看,是头插放在usedpool[奇数],full状态变为used状态
- // free中的代码,
- if (UNLIKELY(lastfree == NULL)) {
- uint size = pool->szidx;
- poolp next = usedpools[size + size]; // 双向链表的尾部
- poolp prev = next->prevpool;
- pool->nextnextpool = next;
- pool->prevprevpool = prev;
- next->prevpool = pool;
- prev->nextpool = pool;
- return 1;
- }
而分配的时候使用是直接从usedpools[偶数]也会就是尾部开始使用的,所以也尽可能用光一个pool的
- // 定位在尾部,直接使用
- poolp pool = usedpools[size + size];
- block *bp;
- if (LIKELY(pool != pool->nextpool)) {
- // block使用数量++
- ++pool->ref.count;
- bp = pool->freeblock; // freeblock指向第一块空闲块,直接使用
- assert(bp != NULL);
分配执行流程
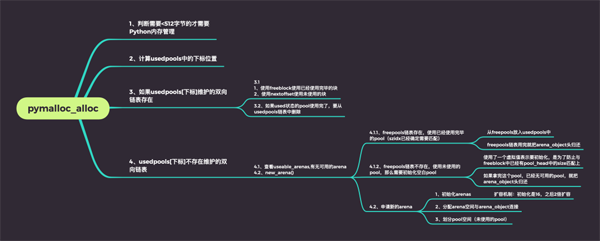
“ 当申请的内存小于512字节就来到这个函数了,他的主要功能是分配block、分配pool、分配arena
- // 下标映射到size大小
- #define INDEX2SIZE(I) (((uint)(I) + 1) << ALIGNMENT_SHIFT)
- // 内存对齐的宏
- #define POOL_OVERHEAD _Py_SIZE_ROUND_UP(sizeof(struct pool_header), ALIGNMENT)
- #define DUMMY_SIZE_IDX 0xffff /* size class of newly cached pools */
- //Objects/obmalloc.c
- static void*
- pymalloc_alloc(void *ctx, size_t nbytes)
- {
- // 1、如果申请的内存>512和==0的情况走朋友python0层,交给C处理
- // 如下是Python来接管这个raw memory,当然raw memory也是由C创建的
- if (UNLIKELY(nbytes == 0)) {
- return NULL;
- }
- if (UNLIKELY(nbytes > SMALL_REQUEST_THRESHOLD)) {
- return NULL;
- }
- // 2、用size去计算usedpools数组中的位置,
- uint size = (uint)(nbytes - 1) >> ALIGNMENT_SHIFT;
- poolp pool = usedpools[size + size];
- block *bp;
- // 如果usedpools中的双向链表有pool那么就分配
- if (LIKELY(pool != pool->nextpool)) {
- // block使用数量++
- ++pool->ref.count;
- bp = pool->freeblock; // freeblock指向第一块空闲块,直接使用
- assert(bp != NULL);
- if (UNLIKELY((pool->freeblock = *(block **)bp) == NULL)) {
- // 如果freeblock是NULL,通过偏移量取未使用的block
- if (UNLIKELY(pool->nextoffset <= pool->maxnextoffset)) {
- pool->freeblock = (block*)pool + pool->nextoffset;
- // 用小标去还原size
- pool->nextoffset += INDEX2SIZE(size);
- *(block **)(pool->freeblock) = NULL;
- return;
- }
- /* 没有可分配的block了,那么从usedpools中删除*/
- poolp next;
- next = pool->nextpool;
- poolpool = pool->prevpool;
- next->prevpool = pool;
- pool->nextnextpool = next;
- }
- // usedpools没有可用的pool,需要去申请
- else {
- bp = allocate_from_new_pool(size);
- }
- // 返回pool内的块
- return (void *)bp;
- }
- #define ROUNDUP(x) (((x) + ALIGNMENT_MASK) & ~ALIGNMENT_MASK)
- #define POOL_OVERHEAD ROUNDUP(sizeof(struct pool_header))
- // 虚拟大值,是为了防止与freepool中的block匹配上,这个虚拟值是标记用来初始化空pool的
- #define DUMMY_SIZE_IDX 0xffff
- static void*
- allocate_from_new_pool(uint size)
- // 0、首先会尝试去usable_arenas双向链表中拿,没有可用的arena时,就调用new_arena()
- // new_arena将arena_object设置到usable_arenas中,因为是第一个所以双向链表指针都置空
- if (usable_arenas == NULL) {
- usable_arenas = new_arena();
- usable_arenas->nextarena = usable_arenas->prevarena = NULL;
- }
- poolp pool = usable_arenas->freepools;
- // 1、freepools链表存在,使用已经使用完毕的pool(szidx已经确定需要匹配)
- // 那么要从freepools中取出,放到usedpools中
- if (pool != NULL) {
- usable_arenas->freepools = pool->nextpool;
- --usable_arenas->nfreepools;
- // freepools用完了,那么使用下个usable_arenas,归还arena_object头
- if (UNLIKELY(usable_arenas->nfreepools == 0)) {
- usable_arenasusable_arenas = usable_arenas->nextarena;
- if (usable_arenas != NULL) {
- usable_arenas->prevarena = NULL;
- }
- }
- }
- // 2、freepools链表不存在,使用未使用的pool,那么需要初始化空白pool
- else {
- pool = (poolp)usable_arenas->pool_address;
- pool->arenaindex = (uint)(usable_arenas - arenas);
- // 设置虚拟值是为了防止与freepool中的block匹配上,这个虚拟值是标记用来初始化空pool的
- pool->szidx = DUMMY_SIZE_IDX;
- usable_arenas->pool_address += POOL_SIZE;
- --usable_arenas->nfreepools;
- // 如果没有可用的pool了把arena_object头归还
- if (usable_arenas->nfreepools == 0) {
- usable_arenasusable_arenas = usable_arenas->nextarena;
- }
- }
- // 无论是情况1还是2都是要返回一块block后,此pool插入usedpools[下标]的双向链表中,并作为第一个pool
- block *bp;
- poolp next = usedpools[size + size]; /* == prev */
- pool->nextnextpool = next;
- pool->prevpool = next;
- next->nextpool = pool;
- next->prevpool = pool;
- pool->ref.count = 1;
- // 使用的是情况1,直接使用freepools(指向第一个已经使用完的pool)链表上的块
- if (pool->szidx == size) {
- bp = pool->freeblock;
- assert(bp != NULL);
- pool->freeblock = *(block **)bp;
- return bp;
- }
- // 使用的情况2,需要初始化pool header的空白pool
- pool->szidx = size;
- // 一个宏, 将szidx转成内存块的大小, 比如: 0->8, 1->16, 63->512
- size = INDEX2SIZE(size);
- // 跳过用于pool_header的内存,并进行对齐
- bp = (block *)pool + POOL_OVERHEAD;
- pool->nextoffset = POOL_OVERHEAD + (size << 1);
- pool->maxnextoffset = POOL_SIZE - size;
- pool->freeblock = bp + size;
- *(block **)(pool->freeblock) = NULL; // 有空闲链表头指向空
- return bp;
- }
这个函数有三个作用,分别是“释放 block”“释放 pool”以及“释放 arena”。
从block搜索pool的技巧
- #define SYSTEM_PAGE_SIZE (4 * 1024)
- #define SYSTEM_PAGE_SIZE_MASK (SYSTEM_PAGE_SIZE - 1)
- #define POOL_SIZE_MASK SYSTEM_PAGE_SIZE_MASK
- // 基于地址P获得离P最近的pool的边界地址
- #define POOL_ADDR(P) ((poolp)_Py_ALIGN_DOWN((P), POOL_SIZE)) //等价如下
- #define POOL_ADDR(P) (P & 0xfffff000)
pool 地址对齐是按 4K 字节对齐的。也就是说,只要从pool 内部某处 block 的地址开始用 0xfffff000 标记,肯定能取到 pool 的开头。
末尾3个0是16^3=4096,取前面几位就一定是4K的倍数


- //Objects/obmalloc.c
- static inline int
- pymalloc_free(void *ctx, void *p)
- {
- poolp pool = POOL_ADDR(p);
- // 负责检查用宏 POOL_ADDR() 获得的 pool 是否正确
- if (UNLIKELY(!address_in_range(p, pool))) {
- return 0;
- }
- // 把需要释放的p,头插到freeblock中
- block *lastfree = pool->freeblock;
- *(block **)p = lastfree;
- pool->freeblock = (block *)p;
- pool->ref.count--;
- // full状态变为used状态,是头插到usedpools中
- if (UNLIKELY(lastfree == NULL)) {
- uint size = pool->szidx;
- poolp next = usedpools[size + size];
- poolp prev = next->prevpool;
- pool->nextnextpool = next;
- pool->prevprevpool = prev;
- next->prevpool = pool;
- prev->nextpool = pool;
- return 1;
- }
- // 还有可分配的block
- if (LIKELY(pool->ref.count != 0)) {
- /* pool isn't empty: leave it in usedpools */
- return 1;
- }
- // 如果释放是最后一块,从used状态变为empty,要加入freepool链表(这是最复杂的情况,走insert_to_freepool函数)
- insert_to_freepool(pool);
- return 1;
- }
在Python2.4之前一直存在内存泄漏的问题,因为python2.4对arena是没有区分"未使用"和可用的2种状态,所以当pool都释放了内存,arena始终不会释放它维护的pool集合。
2.5之后对arena的处理实际上分为了4种情况
- static void
- insert_to_freepool(poolp pool)
- {
- // 从usedpools中取出pool
- poolp next = pool->nextpool;
- poolp prev = pool->prevpool;
- next->prevprevpool = prev;
- prev->nextnextpool = next;
- // 将pool头插到arena中的freepools中
- struct arena_object *ao = &arenas[pool->arenaindex];
- pool->nextpool = ao->freepools;
- ao->freepools = pool;
- uint nf = ao->nfreepools;
- struct arena_object* lastnf = nfp2lasta[nf];
- if (lastnf == ao) { /* it is the rightmost */
- struct arena_object* p = ao->prevarena;
- nfp2lasta[nf] = (p != NULL && p->nfreepools == nf) ? p : NULL;
- }
- ao->nfreepools = ++nf;
- if (nf == ao->ntotalpools && ao->nextarena != NULL) {
- /* 情况1、最后一个block、最后一个pool,最终归还arena_object*/
- // 从usable_arenas取出arena_object
- if (ao->prevarena == NULL) {
- usable_arenas = ao->nextarena;
- }
- else {
- ao->prevarena->nextarena =
- ao->nextarena;
- }
- if (ao->nextarena != NULL) {
- assert(ao->nextarena->prevarena == ao);
- ao->nextarena->prevarena =
- ao->prevarena;
- }
- // 头插到unused_arena_objects链表中
- ao->nextarena = unused_arena_objects;
- unused_arena_objects = ao;
- // 释放内存
- _PyObject_Arena.free(_PyObject_Arena.ctx,
- (void *)ao->address, ARENA_SIZE);
- // “arena尚未被分配”的标记
- ao->address = 0;
- --narenas_currently_allocated;
- return;
- }
- // 情况2、所以有pool是full/used状态,释放一个block使得used-empty状态,就此有唯一的empty状态的pool
- // 需要加入usable_arenas链表中
- if (nf == 1) {
- ao->nextarena = usable_arenas;
- ao->prevarena = NULL;
- if (usable_arenas)
- usable_arenas->prevarena = ao;
- usable_arenas = ao;
- assert(usable_arenas->address != 0);
- if (nfp2lasta[1] == NULL) {
- nfp2lasta[1] = ao;
- }
- return;
- }
- /* If this arena is now out of order, we need to keep
- * the list sorted. The list is kept sorted so that
- * the "most full" arenas are used first, which allows
- * the nearly empty arenas to be completely freed. In
- * a few un-scientific tests, it seems like this
- * approach allowed a lot more memory to be freed.
- */
- /* If this is the only arena with nf, record that. */
- if (nfp2lasta[nf] == NULL) {
- nfp2lasta[nf] = ao;
- /* 情况4、 Nothing to do. */
- if (ao == lastnf) {
- return;
- }
- // 情况3、因为usable_arenas维护的是有序表,插入响应的位置
- if (ao->prevarena != NULL) {
- /* ao isn't at the head of the list */
- ao->prevarena->nextarena = ao->nextarena;
- }
- else {
- /* ao is at the head of the list */
- usable_arenas = ao->nextarena;
- }
- ao->nextarena->prevarena = ao->prevarena;
- /* And insert after lastnf. */
- ao->prevarena = lastnf;
- ao->nextarena = lastnf->nextarena;
- if (ao->nextarena != NULL) {
- ao->nextarena->prevarena = ao;
- }
- lastnf->nextarena = ao;
- /* Verify that the swaps worked. */
- assert(ao->nextarena == NULL || nf <= ao->nextarena->nfreepools);
- assert(ao->prevarena == NULL || nf > ao->prevarena->nfreepools);
- assert(ao->nextarena == NULL || ao->nextarena->prevarena == ao);
- assert((usable_arenas == ao && ao->prevarena == NULL)
- || ao->prevarena->nextarena == ao);
- }
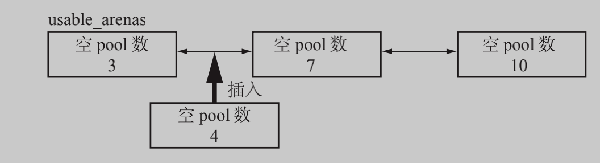
情况3
Python1、2层内存内存管理汇总

对象有列表和元组等多种多样的型,在生成它们的时候要使用各自特有的分配器。见我的其他Python底层数据结构的分析。
【责任编辑:庞桂玉 TEL:(010)68476606】




