

照片来源于 Pexels
文中根据大家对 Loki 的应用和了解,从它造成的情况、处理的难题、选用的计划方案、系统架构图、完成逻辑性等做一些分析,期待对关心 Loki 的朋友们出示一些协助。
在日常的系统软件数据可视化监管全过程中,当监管探索到指标值出现异常时,大家通常必须对难题的根因作出精准定位。
但监管数据信息所曝露的信息内容是提早预置、高宽比提炼出的,在数据量上存有着非常大的不够,它必须融合可以安装丰富多彩信息内容的日志系统软件一起应用。
当视频监控系统探索到出现异常报警,大家一般在 Dashboard 上依据出现异常指标值隶属的群集、服务器、案例、运用、時间等信息内容选定难题的大概方位,随后自动跳转到日志系统软件做更细致的查看,获得更丰富的信息内容来最后分辨难题根因。
在以上步骤中,视频监控系统和日志系统软件通常是单独的,应用方法具备非常大差别。例如视频监控系统 Prometheus 较为火爆,日志系统软件多选用 ES Kibana 。
她们具备彻底不一样的定义、不一样的检索英语的语法和页面,这不但给使用人提升了学习培训成本费,也促使在应用时要在两个系统软件中经常做前后文转换,对难题的精准定位迟缓。
除此之外,日志系统软件多选用全文索引来支撑点站内搜索,它必须为日志的全文创建反方向数据库索引,这会造成 最后储存数据信息相较初始內容成倍增加,造成不容小觑的储存成本费。
而且,无论数据信息未来是不是会被检索,都是会在载入时由于数据库索引实际操作而占有很多的云计算服务器,这针对日志这类写多读少的服务项目毫无疑问也是一种云计算服务器的消耗。
Loki 则是为了更好地解决所述难题而造成的解决方法,它的总体目标是打造出可以与监管深层集成化、成本费极其便宜的日志系统软件。
Loki 日志计划方案
低应用成本费
①数据库系统
在数据库系统上,Loki 参照了 Prometheus ,数据信息由标识、时间格式、內容构成,全部标识同样的数据信息归属于同一日志流:
具备以下构造:
- {
- "stream": {
- "label1": "value1",
- "label1": "value2"
- }, # 标识
- "values": [
- ["<timestamp nanoseconds>","log content"], # 时间格式,內容
- ["<timestamp nanoseconds>","log content"]
- ]
- }
Loki 还适用多租户,同一租赁户下具备完全一致标识的日志所构成的结合称之为一个日志流。
在日志的收集端应用和监管时序数据一致的标识,那样在能够事后与视频监控系统融合时应用同样的标识,也为在 UI 页面中与监管融合应用做迅速前后文转换给出的数据基本。
LogQL:Loki 应用相近 Prometheus 的 PromQL 的查看句子 logQL ,英语的语法简易并接近小区应用习惯性,减少客户学习培训和应用成本费。
英语的语法事例以下:
- {file="debug.log""} |= "err"
流选择符:{label1="value1", label2="value2"}, 根据标识挑选日志流, 适用等、不一、搭配、不搭配等挑选方法。过滤装置:|= "err",过虑日志內容,适用包括、不包含、搭配、不搭配等过虑方法。
这类工作方式类似 find grep,find 找到文档,grep 文本文件中一行行搭配:
- find . -name "debug.log" | grep err
logQL 除适用日志內容查看外,还适用对日志总产量、頻率等汇聚测算。
Grafana:在 Grafana 中华生适用 Loki 软件,将监管和日志查看集成化在一起,在同一 UI 页面中能够对监管数据信息和日志开展 side-by-side 的下钻查看探寻,比应用不一样系统软件不断开展转换更形象化、更方便快捷。
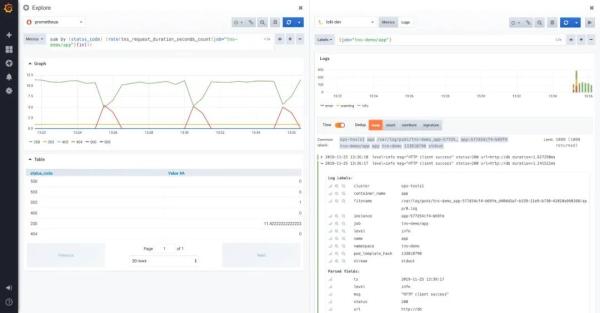
除此之外,在 Dashboard 中能够将监管和日志查看配备在一起,那样可另外查询监管数据信息行情和日志內容,为捕获很有可能存在的不足出示更形象化的方式。
低储存成本费
只数据库索引与日志有关的元数据标签,而日志內容则以压缩方式储存于阿里云oss中, 不做一切数据库索引。
相比于 ES 这类全文索引的系统软件,数据信息可在十倍数量级上减少,再加上应用阿里云oss,最后储存成本费可减少数十倍乃至更低。
计划方案不处理繁杂的分布式存储难题,只是立即运用目前完善的分布式系统系统软件,例如 S3、GCS、Cassandra、BigTable 。
Loki 构架
总体上 Loki 选用了读写分离的构架,由好几个控制模块构成:
其主体工程如下图所显示:
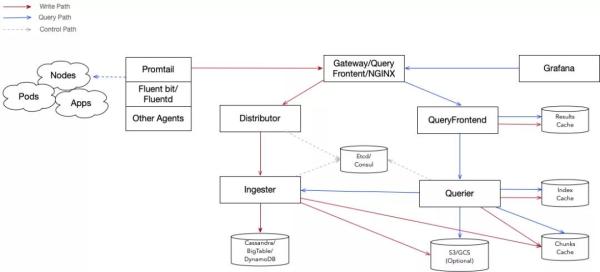
Distributor:做为日志载入的通道服务项目,其承担对汇报数据信息开展分析、校检与分享。
它将接受到的汇报数分析进行后会开展尺寸、内容、頻率、标识、租赁户等主要参数校检,随后将合理合法数据信息分享到 Ingester 服务项目,其在分享以前最重要的每日任务是保证 同一日志流的数据信息务必分享到同样 Ingester 上,以保证 数据信息的次序性。
Hash 环:Distributor 选用一致性哈希与团本因素紧密结合的方法来决策数据信息分享到什么 Ingester 上。
Ingester 在起动后,会形成一系列的 32 位随机数字做为自身的 Token ,随后与这一组 Token 一起将自身申请注册到 Hash 环中。
在挑选数据信息分享到达站时,Distributor 依据日志的标识和租赁户 ID 形成 Hash,随后在 Hash 环中按 Token 的升序搜索第一个超过这一 Hash 的 Token ,这一 Token 所相匹配的 Ingester 即是这条日志必须分享的到达站。
假如设定了团本因素,次序的在以后的 Token 中搜索不一样的 Ingester 作为团本的到达站。
Hash 环可储存于 etcd、consul 中。此外 Loki 应用 Memberlist 完成了群集內部的 KV 储存,如不愿依靠 etcd 或 consul ,可选用此计划方案。
I/O:Distributor 的键入主要是以 HTTP 协议书大批量的方法接纳汇报日志,日志封裝文件格式适用 JSON 和 PB ,数据信息封裝构造:
- [
- {
- "stream": {
- "label1": "value1",
- "label1": "value2"
- },
- "values": [
- ["<timestamp nanoseconds>","log content"],
- ["<timestamp nanoseconds>","log content"]
- ]
- },
- ......
- ]
Distributor 以 grpc 方法向 ingester 传送数据,数据信息封裝构造:
- {
- "streams": [
- {
- "labels": "{label1=value1, label2=value2}",
- "entries": [
- {"ts": <unix epoch in nanoseconds>, "line:":"<log line>" },
- {"ts": <unix epoch in nanoseconds>, "line:":"<log line>" },
- ]
- }
- ....
- ]
- }
①Ingester
做为 Loki 的载入控制模块,Ingester 关键每日任务是缓存文件并载入数据信息到最底层储存。依据载入数据信息在控制模块中的生命期,ingester 大致分成校检、缓存文件、储存兼容三层构造。
②校检
Loki 有一个关键的特点是它不梳理数据信息乱序,规定同一日志流的数据信息务必严格执行时间格式单调递增次序载入。
因此 除对数据信息的长短、頻率等做校检外,尤为重要的是日志次序查验。
Ingester 对每一个日志流里每一条日志都是会和上一条开展时间格式和內容的比照,对策以下:
③缓存文件
日意在运行内存中的缓存文件选用双层树结构对不一样租赁户、日志流作出防护。同一日志流选用次序增加方法载入分层:
总体构造以下:
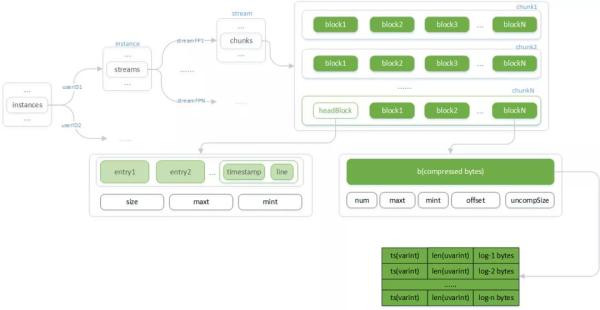
Chunks:在向运行内存载入数据信息前,ingester 最先会依据租赁户ID(userID)和由标识测算的指纹识别(streamPF)精准定位到日志流(stream)及 Chunks。
Chunks 由按時间升序排序的 chunk 构成,最后一个 chunk 接受全新载入的数据信息,别的则等刷写到最底层储存。
当最后一个 chunk 的生存時间或数据信息尺寸超出特定阀值时,Chunks 尾端增加新的 chunk 。
Chunk:Chunk 为 Loki 在最底层储存上读写能力的最少模块在运行内存态下的构造。其由多个 block 构成,在其中 headBlock 为已经对外开放载入的 block ,而别的 Block 则早已存档缩小的数据信息。
Block:Block 为数据信息的缩小模块,目地是为了更好地在载入实际操作那边防止由于每一次缓解压力全部 Chunk 而消耗云计算服务器,由于许多 状况下是载入一个 chunk 的一部分数据信息就考虑所需信息量而回到結果了。
Block 储存的是日志的缩小数据信息,其构造为按先后顺序的日志时间格式和初始內容,缩小可选用 gzip、snappy 、lz4 等方法。
HeadBlock:已经接受载入的独特 block ,它在考虑一定尺寸之后被缩小存档为 Block ,随后新 headBlock 会被建立。
储存兼容:因为最底层储存要适用 S3、Cassandra、BigTable、DnyamoDB 等系统软件,兼容层将各种各样系统软件的存取数据抽象性成统一插口,承担与她们开展数据信息互动。
④輸出
Loki 以 Chunk 为企业在分布式存储中读写能力数据信息。在长久储存态下的 Chunk 具备以下构造:
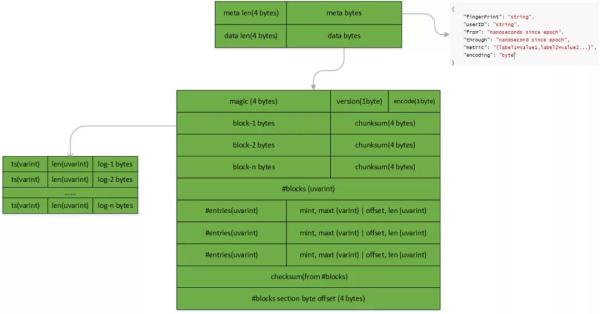
Chunk 数据信息的分析次序:
⑤数据库索引
Loki 只数据库索引了标签数据,用以完成标识→日志流→Chunk 的数据库索引投射, 以分表方式在储存层储存。
表结构以下:
- CREATE TABLE IF NOT EXISTS Table_N (
- hash text,
- range blob,
- value blob,
- PRIMARY KEY (hash, range)
- )
Table_N,依据时间周期分表名;hash, 不一样查看种类时应用的数据库索引;range,范畴查看字段名;value,日志标识的值。
基本数据类型:Loki 储存了不一样种类的数据库索引数据信息用于完成不一样投射情景,针对每个种类的投射数据信息,Hash/Range/Value 三个字段的数据信息构成如下图所显示:

seriesID 为日志流 ID,shard 为分块,userID 为租赁户 ID,labelName 为标识名,labelValueHash 为标识值 hash,chunkID 为 chunk 的 ID,chunkThrough 为 chunk 里最终一条数据信息的時间这种数据信息原素在投射全过程中的功效在 Querier 阶段的[查看步骤]((null))做详解。
图中中三种颜色标志的索引类型从上向下各自为:
除开选用分表外,Loki 还选用分桶、分块的方法提升数据库索引查看速率。
分桶:
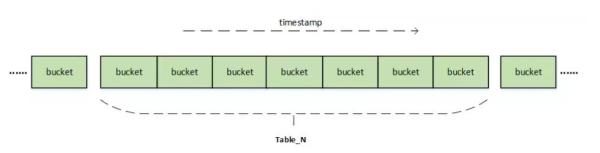
以日切分:bucketID = timestamp / secondsInDay。
以钟头切分:bucketID = timestamp / secondsInHour。
分块:将不一样日志流的数据库索引分散化到不一样分块,shard = seriesID% 分块数。
Chunk 情况:Chunk 做为在 Ingester 中关键的数据信息模块,其在运行内存中的生命期内分以下四种情况:
四种情况中间的变换以 writing→waiting flush→retain→destroy 次序开展。
情况变换机会:
writing 变为 waiting flush:chunk 最初的状态为 writing,标志已经接纳数据信息的载入,考虑以下标准则进到到等候刷写情况:
waiting flush 变为 etain:Ingester 会定时执行的将等候刷写的 chunk 写到最底层储存,以后这种 chunk 会处在”retain“情况,这是由于 ingester 出示了对最新数据的站内搜索,必须在运行内存里保存一段时间,retain 情况则解耦了数据信息的刷写時间及其在运行内存中的保存期,便捷视不一样选择项提升运行内存配备。
destroy,被收购等候 GC 消毁:整体上,Loki 因为对于日志的应用情景,选用了次序增加方法载入,只数据库索引元信息内容,巨大水平上简单化了它的算法设计和解决逻辑性,这也为 Ingester 可以解决髙速载入出示了基本。
Querier:网络查询的实行部件,其承担从最底层储存获取数据信息并依照 LogQL 文学语言叙述的挑选标准过虑。它能够立即根据 API 出示网络查询,还可以与 queryFrontend 融合应用完成分布式系统高并发查看。
⑥查看种类
查看种类以下:
在这种查看种类中,范畴日志查看运用更为普遍,因此 下面只对范畴日志查看做详解。
高并发查看:针对单独查看要求,尽管能够立即启用 Querier 的 API 开展查看,但非常容易会因为大查看造成 OOM,为解决此类难题 querier 与 queryFrontend 融合一起完成查看溶解与多 querier 高并发实行。
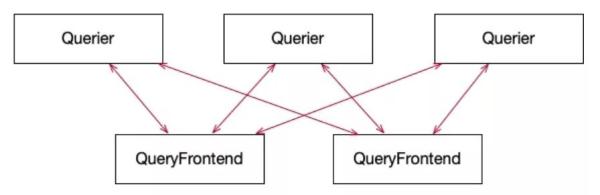
每一个 querier 都和全部 queryFrontend 创建 grpc 双重流式的联接,即时从 queryFrontend 中获得早已切分的子查询求,实行后将結果推送回 queryFrontend。
实际怎样切分查看及在 querier 间生产调度子查询将在 queryFrontend 阶段详细介绍。
⑧查看步骤
先分析 logQL 命令,随后查看日志流 ID 目录。
Loki 依据不一样的标签选择器英语的语法应用了不一样的数据库索引查看逻辑性,大致分成二种:
=,或多值的正则匹配=~,工作中全过程以下:
以相近下 SQL 所叙述的词义查看出标签选择器里引入的每一个标识键值对所相匹配的日志流 ID(seriesID)的结合。
- SELECT * FROM Table_N WHERE hash=? AND range>=? AND value=labelValue
hash 为租赁户 ID(userID)、分桶(bucketID)、标识名(labelName)组合计算的hash值;range 为标识值(labelValue)测算的hash值。
将依据标识键值对所查看的好几个 seriesID 结合取或且或相交求最后结合。
例如,标签选择器{file="app.log", level=~"debug|error"}的工作中全过程以下:
!=,=~,!~,工作中全过程以下:
以以下 SQL 所叙述的词义查看出标签选择器里引入的每一个标识所相匹配 seriesID 结合。
- SELECT * FROM Table_N WHERE hash = ?
hash 为租赁户 ID(userID)、分桶(bucketID)、标识名(labelName)。
依据标识挑选英语的语法对每一个 seriesID 结合开展过虑。
将过虑后的结合开展或且、相交等实际操作求最后结合。
例如,{file~="mysql*", level!="error"} 的工作中全过程以下:
以以下 SQL 所叙述的词义查看出全部日志流所包括的 chunk 的 ID:
- SELECT * FROM Table_N Where hash = ?
hash 为分桶(bucketID)和日志流(seriesID)测算的hash值。
依据 chunkID 目录形成解析xml器来次序载入日志行:解析xml器做为数据信息载入的部件,其关键作用为从分布式存储中拉取 chunk 并从这当中载入日志行。其选用双层树结构,自顶向下逐级递归开启方法弹出来数据信息。
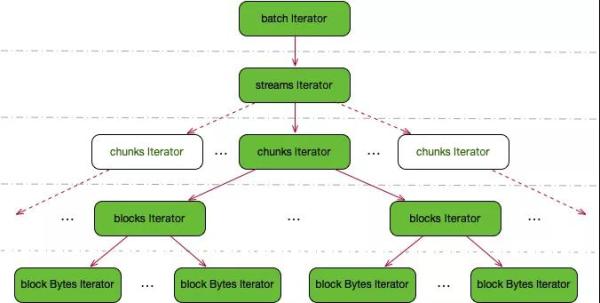
实际构造如圖所显示:
从 Ingester 查看在运行内存中并未载入到储存中的数据信息:因为 Ingester 是定时执行的将缓存文件载入到储存中,因此 Querier 在查看时间段较新的数据信息时,还会继续根据 grpc 协议书从每一个 ingester 中查看出运行内存数据信息。
必须在 ingester 中查看的时间段是可配备的,视 ingester 缓存文件时间而定。
上边是日志內容查看的关键步骤。对于指标查询的步骤两者之间如出一辙,仅仅提升了指标值测算的解析xml器层用以从查看出的日志测算指标值数据信息。别的二种则更加简易,这儿已不详尽进行。
QueryFrontend:Loki 对查看选用了测算后置摄像头的方法,类似在很多原始记录上做 grep,因此 查看必定会耗费比较多的测算和运行内存資源。
假如以单连接点实行一个查看要求得话非常容易由于大查看导致 OOM、速度比较慢等特性短板。
为处理此难题,Loki 选用了将单独查看溶解在好几个 querier 上高并发实行方法,在其中查看要求的溶解和生产调度则由 queryFrontend 进行。
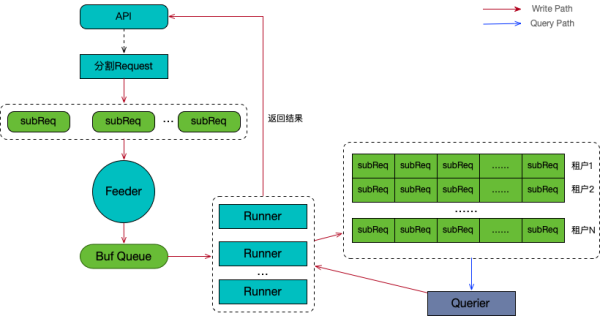
queryFrontend 在 Loki 的总体构架上处在 querier 的前端开发,它做为数据信息载入实际操作的通道服务项目,其关键的部件及工作内容如圖所显示:
⑨查看切分
queryFrontend 依照固定不动周期时间将查看要求切分成好几个子查询。例如,一个查看的时间段是 6 钟头,切分跨距为 15 分鐘,则查看会被分成 6*60/15=24 身高查看。
⑩查看生产调度
Feeder:Feeder 承担将切分好的子查询逐一的载入到缓存文件序列 Buf Queue,以经营者/顾客方式与中下游的 Runner 完成可控性的子查询高并发。
Runner:从 Buf Queue 中市场竞争方法载入子查询并载入到中下游的要求序列中,并解决来源于 Querier 的回到結果。
Runner 的高并发数量根据全局性配备操纵,防止由于一次溶解过多子查看而对 Querier 导致极大的徒总流量,危害其可靠性。
子查询序列:序列是一个二维构造,第一维储存的是不一样租赁户的序列,第二维储存同一租赁户子查询目录,他们全是以 FIFO 的次序机构里边的原素的入队出队。
分派要求:queryFrontend 是以处于被动方法分派查看要求,后端开发 Querier 与 queryFrontend 即时的根据 grpc 监视子查询序列,当有新要求时以以下次序在序列中枪出下一个要求:
汇总
Loki 做为一个已经迅速发展趋势的新项目,最新版已到 2.0,相较 1.6 提高了例如日志分析、Ruler、Boltdb-shipper 等新作用,但是基础的控制模块、构架、数据库系统、原理上已处在平稳情况。
期待文中的这种探究性学习的分析可以可以为大伙儿出示一些协助,如原文中有了解不正确之处,热烈欢迎不吝赐教。
创作者:张海军
编写:陶家龙
出處:转载微信公众号京东商城智联网云开发人员(ID:JDC_Developers)






