

文中转载微信公众平台「五分钟学互联网大数据」,创作者园陌。转截文中请联络五分钟学互联网大数据微信公众号。
招聘者:说下你了解的MPP构架的测算模块?
这个问题许多小伙伴们在招聘面试时都遇到过,由于对MPP这一定义掌握较少,许多人都卡住了,可是大家常见的互联网大数据测算模块有很多全是MPP构架的,像大家了解的Impala、ClickHouse、Druid、Doris等全是MPP构架。
选用MPP构架的许多OLAP模块称为:亿级秒开。
文中分成三一部分解读,第一部分详细说明MPP构架,第二一部分分析MPP构架与批处理命令构架的不同点点,第三一部分是选用MPP构架的OLAP模块详细介绍。
MPP是系统架构图视角的一种网络服务器分类方法。
现阶段商业的网络服务器归类大致有三种:
SMP(对称性多处理器构造)
NUMA(非一致储存浏览构造)
MPP(规模性并行计算构造)
大家今日的主人公是 MPP,由于伴随着分布式系统、并行处理化技术性完善运用,MPP模块慢慢主要表现出强劲的高吞吐、低延迟数学计算,有很多选用MPP构架的模块都能做到“亿级秒开”。
先掌握下这三种构造:
即对称性多处理器构造,是指网络服务器的好几个CPU对称性工作中,无次序或主从关系。SMP网络服务器的关键特点是共享资源,系统软件中的全部資源(如CPU、运行内存、I/O等)全是共享资源的。也恰好是因为这类特点,造成 了SMP网络服务器的关键难题,即拓展工作能力十分比较有限。
即非一致储存浏览构造。这类构造便是为了更好地处理SMP拓展能力不足的难题,运用NUMA技术性,能够把几十个CPU组成在一台网络服务器内。NUMA的本质特征是有着好几个CPU控制模块,连接点中间能够根据互连控制模块开展联接和信息内容互动,因此 ,每一个CPU能够浏览全部系统软件的运行内存(它是与MPP系统软件的关键差别)。可是浏览的速率是不一样的,由于CPU浏览当地运行内存的速率远远地高过系统软件内别的连接点的内存速度,这也是是非非一致储存浏览NUMA的来历。
这类构造也是有一定的缺点,因为浏览外地运行内存的延迟远远地超出浏览当地运行内存,因而,当CPU总数提升时,系统软件特性没法线形提升。
即规模性并行计算构造。MPP的系统软件拓展和NUMA不一样,MPP是由几台SMP网络服务器根据一定的连接点互联网开展联接,协调工作,进行同样的每日任务,从客户的视角看来是一个网站服务器。每一个连接点只浏览自身的資源,因此 是一种彻底无共享资源(Share Nothing)构造。
MPP构造拓展能力最强,基础理论能够无尽拓展。因为MPP是几台SPM服务器连接的,每一个连接点的CPU不可以浏览另一个连接点运行内存,因此 也不会有外地浏览的难题。
MPP框架图:

MPP构架
每一个连接点内的CPU不可以浏览另一个连接点的运行内存,连接点中间的信息内容互动是根据连接点互联网完成的,这一全过程称之为数据信息重分派。
可是MPP网络服务器必须一种繁杂的体制来生产调度和均衡每个连接点的负荷和并行计算全过程。现阶段,一些根据MPP技术性的网络服务器通常根据系统软件级手机软件(如数据库查询)来屏蔽掉这类多元性。举个事例,Teradata便是根据MPP技术性的一个关系型数据库手机软件(它是最开始选用MPP构架的数据库查询),根据此数据库查询来开发设计运用时,无论后台管理网络服务器由是多少连接点构成,开发者应对的全是同一个数据库管理,而不用考虑到怎样生产调度在其中某好多个连接点的负荷。
MPP构架特点:
NUMA和MPP差别:
二者有很多共同之处,最先NUMA和MPP全是由好几个连接点构成的;次之每一个连接点都是有自身的CPU,运行内存,I/O等;都能够都过连接点互连体制开展信息内容互动。
那他们的差别是什么呢,最先是连接点互连体制不一样,NUMA的连接点互连是在同一台物理服务器內部完成的,MPP的连接点互连是在不一样的SMP网络服务器外界根据I/O完成的。
次之是运行内存浏览体制不一样,在NUMA网络服务器內部,一切一个CPU都能够浏览全部系统软件的运行内存,但外地运行内存浏览的特性远远地小于当地运行内存浏览,因而,在开发设计应用软件时应当尽量减少外地运行内存浏览。而在MPP网络服务器中,每一个连接点只浏览当地运行内存,不会有外地运行内存浏览难题。
批处理命令构架(如 MapReduce)与MPP构架的不同点点,及其他们分别的优点和缺点是什么呢?
相同之处:
批处理命令构架与MPP构架全是分布式系统并行计算,将每日任务并行处理的分散化到好几个网络服务器和连接点上,在每一个连接点上测算进行后,将分别一部分的結果归纳在一起获得最后的結果。
不同之处:
批处理命令构架和MPP构架的不同之处能够举例来说:大家实行一个每日任务,最先这一每日任务会被分为好几个task实行,针对MapReduce而言,这种tasks被任意的分派在空余的Executor上;而针对MPP构架的模块而言,每一个解决数据信息的task被关联到拥有该数据信息切成片的特定Executor上。
恰好是因为之上的不一样,促使二种构架有分别优点也是有分别缺点:
针对批处理命令构架而言,假如某一Executor实行太慢,那麼这一Executor会渐渐地分派到更少的task实行,批处理命令构架有一个推断实行对策,推断出某一Executor实行太慢或是有常见故障,则在下面分派task时便会较少的分派给它或是立即不分派,那样就不容易由于某一连接点发生难题而造成 群集的特性受到限制。
一切事儿全是有成本的,针对批处理命令来讲,它的优点也导致了它的缺陷,会将正中间結果载入到硬盘中,这比较严重限定了解决数据信息的特性。
MPP构架不用将正中间数据信息载入硬盘,由于一个单一的Executor只解决一个单一的task,因而能够简易立即将数据信息stream到下一个实行环节。这一全过程称之为pipelining,它出示了非常大的特性提高。
针对MPP构架而言,由于task和Executor是关联的,假如某一Executor实行太慢或常见故障,可能造成 全部群集的特性便会受制于这一常见故障连接点的实行速率(说白了木盆的短板效应),因此 MPP构架的较大 缺点便是——短板效应。另一点,群集中的连接点越多,则某一连接点发生难题的几率越大,而一旦有连接点发生难题,针对MPP构架而言,将造成 全部群集特性受到限制,因此 一般具体生产制造中MPP构架的群集连接点不容易太多。
举个事例而言下二种构架的数据信息落盘:要完成2个大表的join实际操作,针对批处理命令来讲,如Spark可能写硬盘三次(第一次载入:表1根据join key开展shuffle;第二次载入:表2依据join key开展shuffle;第三次载入:Hash表载入硬盘), 而MPP只必须一次载入(Hash表载入)。这是由于MPP将mapper和reducer另外运作,而MapReduce将他们分为有相互依赖的tasks(DAG),这种task是多线程实行的,因而务必根据载入正中间数据信息共享内存来处理数据信息的依靠。
批处理命令构架和MPP构架结合:
2个构架的优点和缺点都很显著,而且他们有相辅相成关联,如果我们能将二者融合起來应用,是否就能充分发挥分别较大 的优点。现阶段批处理命令和MPP也的确已经慢慢迈向结合,也早已拥有一些方案设计,技术性完善后,很有可能会盛行互联网大数据行业,大家翘首以待!
选用MPP构架的OLAP模块有很多,下边只挑选普遍的好多个模块比照下,能为企业的技术选型出示参照。
选用MPP构架的OLAP模块分成两大类,一类是本身不储存数据信息,只承担测算的模块;一类是本身既储存数据信息,也承担测算的模块。
1. Impala
Apache Impala是选用MPP构架的查看模块,自身不储存一切数据信息,立即应用运行内存开展测算,兼具数据库管理,具备即时,批处理命令,多高并发等优势。
出示了类SQL(类Hsql)英语的语法,在多客户情景下也可以有着较高的响应时间和货运量。它是由Java和C 完成的,Java出示的查看互动的插口和完成,C 完成了查看模块一部分。
Impala适用共享资源Hive Metastore,但沒有再应用迟缓的 Hive MapReduce 批处理命令,只是根据应用与商业并行处理关系型数据库中相近的分布式系统查看模块(由 Query Planner、Query Coordinator 和 Query Exec Engine 三一部分构成),能够立即从 HDFS 或 HBase 选用 SELECT、JOIN 和统计函数查看数据信息,进而大幅度降低了延迟时间。
Impala常常配搭储存模块Kudu一起出示服务项目,那么做较大 的优点是查看较为快,而且适用数据信息的Update和Delete。
Presto是一个分布式系统的选用MPP构架的查看模块,自身并不储存数据信息,可是能够连接多种多样数据库,而且适用跨数据库的联级查看。Presto是一个OLAP的专用工具,善于对海量信息开展繁杂的剖析;可是针对OLTP情景,并并不是Presto所善于,因此 不必把Presto作为数据库查询来应用。
Presto是一个低延迟时间分布式系统的运行内存测算模块。必须从别的数据库读取数据来开展计算剖析,它能够联接多种多样数据库,包含Hive、RDBMS(Mysql、Oracle、Tidb等)、Kafka、MongoDB、Redis等。
1. ClickHouse
ClickHouse是近些年备受关注的开源系统列式数据库查询,关键用以数据统计分析(OLAP)行业。
它自包括了储存和数学计算,彻底独立完成了高可用性,并且适用详细的SQL英语的语法包含JOIN等,技术性上拥有显著优点。对比于hadoop管理体系,以数据库查询的方法来做数据融合更为简易实用,学习培训低成本且灵便度提高。当今小区依然在飞速发展中,而且在中国小区也十分火爆,每个大型厂陆续跟踪规模性应用。
ClickHouse在预估层干了十分细腻的工作中,竭尽全力吸干硬件配置工作能力,提高查看速率。它完成了单机版多核并行处理、分布式计算、向量化分析实行与SIMD命令、代码生成等多种多样关键技术性。
ClickHouse从OLAP情景要求考虑,订制开发设计了一套全新升级的高效率列式储存模块,而且完成了数据信息井然有序储存、主键数据库索引、稀少数据库索引、数据信息Sharding、数据信息Partitioning、TTL、主备拷贝等丰富多彩作用。之上作用一同为ClickHouse急速的剖析特性确立了基本。
2. Doris
Doris是百度搜索核心的,依据Google Mesa毕业论文和Impala新项目改变的一个数据分析模块,是一个大量分布式系统 KV 分布式存储,其设计方案总体目标是适用中等水平经营规模高可用性可伸缩式的 KV 储存群集。
Doris能够完成海量存储,线形伸缩式、光滑扩充,全自动容错机制、常见故障迁移,分布式系统,且运维管理低成本。布署经营规模,提议布署4-100 台网络服务器。
Doris3 的关键构架:DT(Data Transfer)承担数据信息导进、DS(Data Seacher)控制模块承担数据统计、DM(Data Master)控制模块承担群集元数据管理,数据信息则储存在 Armor 分布式系统 Key-Value 模块中。Doris3 依靠 ZooKeeper 储存数据库,进而别的控制模块依靠 ZooKeeper 保证了无状态,从而全部系统软件可以保证没有问题点射。
3. Druid
Druid是一个开源系统、分布式系统、朝向列式储存的即时分析数据分布式存储。
Druid的重要特点以下:
4. TiDB
TiDB 是 PingCAP 企业独立设计方案、产品研发的开源系统分布式系统关联型数据库查询,是一款另外适用OLTP与OLAP的结合型分布式系统数据库查询商品。
TiDB 兼容 MySQL 5.7 协议书和 MySQL 绿色生态等关键特点。总体目标是为客户出示一站式 OLTP 、OLAP 、HTAP 解决方法。TiDB 合适高可用性、强一致规定较高、数据信息经营规模很大等各种各样应用领域。
5. Greenplum
Greenplum 是在开源系统的 PostgreSQL 的基本上选用了MPP构架的特性十分强劲的关联型分布式系统数据库查询。为了更好地兼容Hadoop绿色生态,又发布了HAWQ,剖析模块保存了Greenplum的性能卓越模块,下一层储存不会再选用当地电脑硬盘而改成HDFS,避开当地电脑硬盘稳定性差的难题,另外融进Hadoop绿色生态。
一张图小结下常见的OLAP模块比照:
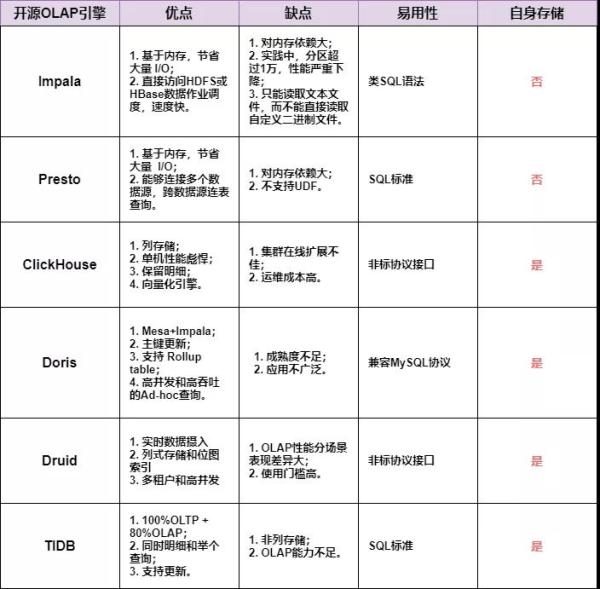
普遍OLAP模块比照





